

در این بخش از دوره آموزشی تست نفوذ سطح متوسط که برگرفته از دوره SEC642 می باشد به ادامه مبحث آشنایی با Blind SQL Injection می پردازیم.
blind sql injection
مجموعه بعدی محدودیتهای ما در خروجی یک پرس وجوی SQL بازگشتی توسط یک برنامه کاربردی وب به عنوان یک تزریق SQL کور طبقهبندی میشود. این شکل از تزریق SQL به این صورت تعریف میشود، نه به دلیل فقدان کامل خروجی، بلکه به این دلیل که هیچ متن واقعی از خروجی پایگاهداده در صفحه نمایش داده نمیشود. در عوض، ما از دیگر شاخصها برای تعیین خروجی پرس و جوی پایگاهداده استفاده میکنیم.
در نوع آسانتر تزریق SQL کور، اگر چه هیچ خروجی مستقیمی از Query وجود ندارد، ما هنوز میتوانیم تعیین کنیم که آیا Query معتبر است یا خیر. آیا این Query هیچ نتیجهای به همراه نداشت؟ سپس از این تمایز صحیح یا اشتباه برای بررسی خروجی Query و تعیین محتویات آن استفاده میشود. این تکنیک معمولا به عنوان تزریق SQL کور مبتنی بر Boolean شناخته میشود.
برای تطبیق دادن این رویکرد مبتنی بر Boolean، باید پرس و جوی نمونه خود را کمی اصلاح کنیم. به جای پرس و جوی نمونه SELECT ‘data’، ما در عوض از شرط استفاده خواهیم کرد. درستی یا نادرستی این شرط برای تعیین اینکه چه چیزی توسط Query برگشت داده میشود، استفاده میشود.
بیایید تا نگاهی به یک مثال جزئی در این خصوص داشته باشیم. شرطی که میتواند محتوای خروجی Query را به ما بگوید، یک مقایسه ساده است. آیا خروجی پرس وجو برابر با رشته Y هست؟
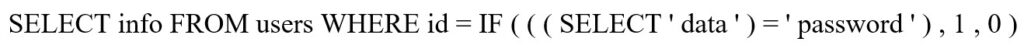
اگر صفحه یک نتیجه معتبر را برگرداند، میدانیم که خروجی معادل password است؛ در غیر این صورت، این مقدار صحیح نیست. این یک مثال ساده است، بنابراین نگاه کنید که چگونه میتوانیم از خروجی مبتنی بر Boolean برای تعیین نتایج هر Query استفاده کنیم.
boolean output to anything
ما خروجی Boolean ای داریم که نتیجه یک عبارت شرطی را به ما نشان میدهد. حالا چی؟ چگونه میتوانیم از این برای تعیین نتایج هر Query استفاده کنیم؟ برای هر یک از روشهای انجام این کار که پوشش میدهیم، تلاش میکنیم تا QPL یا Query per letter را به حداقل برسانیم. به حداقل رساندن QPL مهم است، زیرا ما نمیخواهیم سیستمهای هدف را دچار اضافهبار کنیم یا فعالیت ما به عنوان حمله انکار سرویس شناسایی شده و منجر به مسدود شدن دسترسی ما گردد.
اساسیترین حملهای که میتوانیم انجام دهیم یک حمله دیکشنری در برابر خروجی پرس وجوی SQL است.
به دلیل تعداد زیاد احتمالات خروجی، فرهنگ لغت ما باید متناسب با دادههایی باشد که ما سعی در خواندن آنها را داریم. این حمله میتواند در برابر مقادیر رایج مورد استفاده مانند نامهای کاربری، رمز عبور، نام جدول و ستون، شماره نسخه پایگاههای داده و هر مقدار دیگری که بتوان مجموعه مقادیر بالقوه را پیشبینی کرد، موثر باشد. QPL این حمله به شدت متغیر است و کاملا به این بستگی دارد که فرهنگ لغت تا چه حد با نتایج جستجو مطابقت دارد. همچنین ممکن است بتوان با تبدیل تمام کاراکترها به بزرگ یا کوچک،QPL را کاهش داد. این کار برای گذرواژهها جواب نمیدهد. با این حال، ممکن است برای مجموعه دیگری از رشتههای کاراکترها موفقیت آمیز باشد.
حمله دیگری که از حوزه شکستن رمز عبور ناشی میشود، حمله Brute Force است. مجموعهای از پرس وجوها برای هر مقدار ممکن از طریق استفاده از عبارت ASCII امکان پذیر است.
آیا اولین کاراکتر از خروجی برابر با a است؟ برابر با b است؟ یا برابر c ؟ (c)
آیا دومین کاراکتر از خروجی برابر با a است؟ (a)
آیا سومین کاراکتر از خروجی برابر با a است؟ b؟ c؟ d؟ e؟ f؟ g؟ h؟ i؟ j ؟ k؟ l؟ m؟ n؟ o؟ p؟ q؟ r؟ s؟ t؟ (t)
نتیجه cat است.
QPL این روش تقریبا ۳۱ است اگر خروجی تنها شامل کاراکترهای الفبایی باشد و تقریبا ۶۴ است اگر خروجی بتواند شامل هر کاراکتر اسکی باشد. اگر خروجی حاوی نویسههای یونیکد باشد،QPL حتی بیشتر بالا میرود.
boolean to heuristic brute force
از آنجایی که ما میتوانیم نتیجه یک Query را در یک زمان تعیین کنیم، میتوانیم از یک تکنیک اکتشافی heuristic brute-force که توسط Dmitry Evteev، Vladimir و Voronzov در سال ۲۰۱۰ ایجاد شدهاست، استفاده کنیم. یافتههای آنها در یک مقاله نوشته شده است:
www.exploit-db.com/papers/13696
در حمله Brute Force، ما ارزش هر کاراکتر در خروجی را با یک سری از کاراکترها که از a شروع و به z ختم میشوند، مقایسه میکنیم. اگر چه این کار ساده است، اما با در نظر گرفتن این که در زبان انگلیسی برخی کاراکترها بیشتر از دیگران ظاهر میشوند، میتوان آن را کارآمدتر ساخت. اگر فهرست حروف مقایسهای خود را اصلاح کنیم، با قرار دادن حروف محتملتر مانند”e”، “t” و “a” در ابتدا، میتوانیم QPL را کاهش دهیم.
با این حال، ما میتوانیم این گام را فراتر ببریم. نه تنها باید لیست کاراکترهای Brute Force خود را براساس فرکانس کلی کاراکترها تغییر دهیم، بلکه باید لیست کاراکترهای Brute Force خود را نیز با احتمال ظاهر شدن یکی از کاراکترها بلافاصله پس از دیگری تنظیم کنیم. برای مثال، اولین حرف یک کلمه معمولا حرف “t” است. به طور مشابه، اگر حرف قبلی “q” بود، به طور باورنکردنی احتمال دارد که حرف بعدی “u” باشد. این امر میتواند QPL را هنگام تلاش برای پردازش خروجی به شدت کاهش دهد.
QPL برای این حمله برای خروجی الفبایی عددی تقریباً 20 است و برای خروجی حاوی سایر نویسههای ASCII یا قابل اعمال نیست یا همان نیروی brute است.
boolean to binary search tree
در نهایت، زمانی که تنها یک خروجی درست / غلط بولین دریافت میکنیم، به روشی میرسیم که به طور گسترده به عنوان کارآمدترین روش برای تعیین نتیجه یک پرس و جوی پایگاهداده در نظر گرفته میشود.
با ساختن آنچه که اساسا یک درخت جست و جوی باینری از تمام مقادیر ممکن کاراکتر ASCII است، مقدار ASCII کاراکترها را تعیین کنیم. این فرآیند شبیه یک بازی است که در آن یک بازیکن به یک عدد از ۱ تا ۱۰۰ فکر میکند و بازیکن دوم باید آن را حدس بزند. بازیکن دوم این کار را با پرسیدن سوالاتی مانند ” آیا عددی که شما به آن فکر میکنید بیش از ۵۰ است؟” انجام میدهد. این امر تا زمانی ادامه مییابد که تنها دو انتخاب باقی بماند و سوال نهایی تعیین میکند که کدام یک از این دو صحیح است.
ما میتوانیم کاری مشابه با مقادیر ASCII را در یک پرس و جوی SQL انجام دهیم. با انجام یک سری از مقایسههای “بزرگتر از” بر روی مقدار اسکی هر کاراکتر در خروجی، میتوانیم تعیین کنیم که هر کاراکتر چیست. مثالهای زیر نشان میدهند که چگونه میتوان آنها را جدا کرد، به ASCII تبدیل کرد و کاراکتر خروجی را شناسایی کرد.
در تصویر زیر عبارت [c] برابر با موقعیت کاراکتر مورد نظر است:


با فرض اینکه خروجی ما تنها شامل حروف بزرگ الفبایی با مقادیر اسکی ۶۵ – ۹۵ باشد، با این سوال شروع میکنیم که آیا مقدار ASCII اولین کاراکتر مقدار اسکی ۷۹ است یا خیر. اگر Query درست باشد، یک پاسخ معتبر خواهیم داشت. بدین صورت ما میدانیم که کاراکتر باید بین P و Z، مقادیر اسکی ۸۰ و ۹۵ باشد. سوال بعدی ما این است که آیا مقدار اسکی شماره ۸۶ است یا خیر، و دوباره فضای جستجو را به یک نیم تقسیم کنیم. اگر اولین Query غلط باشد، یک پاسخ نامعتبر داریم. بدین صورت ما میدانیم که کاراکتر باید بین مقادیر A وO، مقادیر اسکی ۶۵ و ۷۹ باشد، و سوال بعدی ما بررسی خواهد شد که آیا مقدار اسکی ۷۱ است یا خیر. دوباره فضای جستجو نصف میشود. این امر تا زمانی ادامه مییابد که تنها یک احتمال باقی بماند.
QPL برای این روش معادل با تعداد بیتهای مورد نیاز برای ذخیره هر کاراکتر است. توجه داشته باشید که در هر مرحله، ما یک عملیات دودویی ۰ یا ۱ را در فضای جستجو اجرا میکنیم که درست مانند نوشتن یک عدد دودویی است. برای کل فضای کاراکترهای اسکی، ما تنها به ۷ بیت برای نمایش یک کاراکتر اسکی نیاز داریم.
