

مرور متافایلهای وب سرور برای یافتن نشتی اطلاعات
در این بخش از دوره آموزشی OWASP-OTG به اولین بخش از استاندارد OTG با شناسه OTG-INFO-003 می پردازیم که مربوط به جمع آوری اطلاعات متا از وب سرور برای یافتن نشت اطلاعات می باشد.
خلاصه
در OTG-INFO-003 به بررسی نحوه آنالیز فایل robots.txt برای نشتی اطلاعات مسیرها و دایرکتوریهای وب اپلیکیشن میپردازد. در ادامه نیز لیستی از دایرکتوریهایی که توسط اسپایدرها، رباتها و کرالرها باید نادیده گرفته شوند ساخته خواهد شد.
اهداف تست و ارزیابی
- یافتن نشت اطلاعاتی از مسیرها و دایرکتوریهای وب اپلیکیشن
- ایجاد لیستی از دایرکتوریهایی که اسپایدرها، رباتها و کرالرها باید آنها را نادیده بگیرند.
چگونه تست کنیم؟
Robots.txt
اسپایدرها، رباتها و کرالرها صفحه وبی را گرفته و لینکهای آن را به طور بازگشتی پیمایش میکنند تا محتوای بیشتری از آن کسب کنند. رفتار مورد قبول برای آنها در پروتکل ممنوعیت رباتها در فایل robots.txt واقع در دایرکتوری ریشه وب مشخص میشود.
به عنوان مثال، چند خط ابتدایی فایل robots.txt سایت گوگل واقع در آدرس http://www.google.com/robots.txt در تاریخ 11 آگوست 2013 در ادامه آورده شده است:
User-agent: *
Disallow: /search
Disallow: /sdch
Disallow: /groups
Disallow: /images
Disallow: /catalogs
…
عبارت User-Agent به اسپایدر، ربات و کرالر اشاره دارد. به عنوان مثال، User-Agent: Googlebot به اسپایدر گوگل و User-Agent: bingbot به کرالر مایکروسافت/یاهو اشاره دارند. User-Agent: * به تمامی اسپایدرها، رباتها و کرالرها اشاره دارد.
عبارت Disallow مشخص میکند که چه منابعی توسط اسپایدرها، رباتها و کرالرها منع میشوند.
اسپایدرها، رباتها و کرالرها میتوانند عمداً عبارت و دستور Disallow در فایل robots.txt سایتهایی مانند شبکههای اجتماعی را نادیده بگیرند تا مطمئن شوند که لینکهای به اشتراک گذاشته شده معتبر هستند. به همین علت، robots.txt نباید به عنوان یک مکانیزم برای اعمال محدودیت بر نحوه دسترسی، ذخیرهسازی و انتشار محتوای وب توسط عوامل شخص ثالث تلقی شود.
Robots.txt در webroot – با استفاده از wget یا curl
فایل robots.txt از دایرکتوری ریشه وب سرور گرفته میشود. به عنوان مثال، برای گرفتن فایل robots.txt واقع در www.google.com با استفاده از wget یا curl به نحو زیر عمل میکنیم:
cmlh$ wget http://www.google.com/robots.txt
–2013-08-11 14:40:36– http://www.google.com/robots.txt
Resolving www.google.com… 74.125.237.17, 74.125.237.18, 74.125.237.19, …
Connecting to www.google.com|74.125.237.17|:80… connected.
HTTP request sent, awaiting response… 200 OK
Length: unspecified [text/plain]
Saving to: ‘robots.txt.1’
2013-08-11 14:40:37 (59.7 MB/s) – ‘robots.txt’ saved [7074]
cmlh$ head -n5 robots.txt
User-agent: *
Disallow: /search
Disallow: /sdch
Disallow: /groups
Disallow: /images
cmlh$
cmlh$ curl -O http://www.google.com/robots.txt
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
101 7074 0 7074 0 0 9410 0 –:–:– –:–:– –:–:– 27312
cmlh$ head -n5 robots.txt
User-agent: *
Disallow: /search
Disallow: /sdch
Disallow: /groups
Disallow: /images
cmlh$
Robots.txt در webroot – با استفاده از rockspider
ابزار rockspider فرایند ساخت محدوده و دامنه اولیه فایلها و دایرکتوریها را برای اسپایدرها، رباتها و کرالرها به طور خودکار انجام میدهد. به عوان مثال، برای ساخت یک دامنه اولیه مبنی برای دستور Allowed: از سایت www.google.com به نحو زیر عمل میکنیم:
cmlh$ ./rockspider.pl -www www.google.com
“Rockspider” Alpha v0.1_2
Copyright 2013 Christian Heinrich
Licensed under the Apache License, Version 2.0
Downloading http://www.google.com/robots.txt
“robots.txt” saved as “www.google.com-robots.txt”
Sending Allow: URIs of www.google.com to web proxy i.e. 127.0.0.1:8080
/catalogs/about sent
/catalogs/p? sent
/news/directory sent
…
Done.
cmlh$
آنالیز robots.txt با استفاده از ابزارهای گوگل وب مستر
مالکان و صاحبان وبسایتها از تابع Analyze robots.txt گوگل که بخشی از ابزار وب مستر گوگل به آدرس https://www.google.com/webmasters/tools است، استفاده میکنند تا وبسایتشان را بررسی و آنالیز کنند. این ابزار میتواند در تست و ارزیابی کمک کند. فرایند استفاده از این ابزار به شرح زیر است:
- با استفاده از اکانت گوگل خود وارد بخش ابزار گوگل وب مستر شوید.
- در داشبورد باز شده، آدرس سایتی که میخواهید آنالیز شود را وارد کنید.
- یکی از روشهای موجود را انتخاب کرده و دستورالعملهای آن را اجرا کنید.
تگ META
تگهای META در بخش HEAD سند HTML قرار دارند و باید در همه جای وب سایت ثابت و یکسان باشند تا نقطهی شروع اسپایدر، ربات و کرالر جایی به غیر از ریشه وبسایت نباشد.
اگر دستور META NAME=”ROBOTS” … وجود نداشته باشد، پروتکل ممنوعیت رباتها به طور پیشفرض عمل INDEX, FOLLOW را انجام میدهد. برای نقض این فرایند میتوان عبارت NO را در ابتدای رکوردهای این پروتکل مانند NOINDEX و NOFOLLOW اضافه کرد.
اسپایدرها، رباتها و کرالرها میتوانند تگ META NAME=”ROBOTS” را عمداً نادیده بگیرند. به همین علت، تگهای META نباید به عنوان مکانیزم اصلی؛ بلکه باید به عنوان مکانیزم مکمل برای کنترل robots.txt تلقی شوند.
تگهای META – با استفاده از Burp
با تکیه بر دستورهای Disallow لیست شده در فایل robots.txt، یک جست و جوی META NAME=”ROBOTS” در داخل هر صفحه انجام گرفته و نتیجه آن با robots.txt واقع در دایرکتوری ریشه مقایسه میشود.
به عنوان مثال، robots.txt فیسبوک حاوی یک خط دستور Disallow: /ac.php است و نتیجه جست و جو عبارت META NAME=”ROBOTS” در زیر آورده شده است:
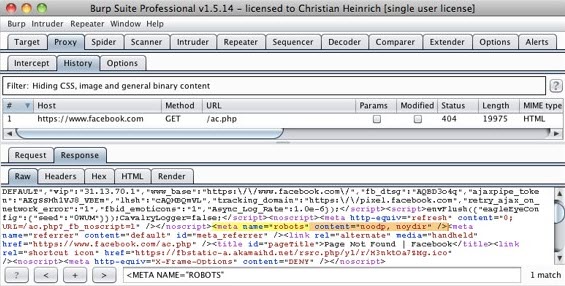
شاید به نظر برسد که نتیجه جست و جوی فوق ناموفق باشد چرا که INDEX, FOLLOW مقدار پیشفرض مشخص شده توسط پروتکل ممنوعیت رباتها برای تگ META است در حالیکه Disallow: /ac.php در robots.txt لیست شده است.
ابزارها
• مرورگر
• curl
• wget
• rockspider
مطالب این بخش توسط جناب آقای امیر ثروتی تهیه شده است.


